🗨 About Me
Hi, I'm Boyi Li. I am pursuing my dual B.S. degree in Computer Engineering at Zhejiang University and University of Illinois Urbana-Champaign.I'm currently a research intern in the Rehg Lab at UIUC, deeply honored to be mentored by Yifan Shen, Xu Cao, and Prof. James M. Rehg. Previously, I was very fortunate to be a research assistant in CVNext Lab at Zhejiang University, mentored by Zhonghan Zhao and Prof. Gaoang Wang. I am grateful to them for their help and support in my early research journey and development.
Research Interests:
- Cognition-inspired multimodal learning and world models
- Multi-agent communication optimization
- Foundation models for healthcare
Future Plans:
I am currently seeking a PhD position starting in 2027 Fall, mainly foucus on the field of cognition-inspired multimodel learning. If my background aligns with your research, please contact with me, and I would be grateful to be considered and have a meeting with you if possible. I am also happy to discuss relevant potential research fit and collaboration opportunities.My Resume
🌎 Service
Reviewer:
- Conferences: KDD 2026 (AI4Science Track), KDD 2027 (AI4Science Track).
- Workshops: CVPR 2026 @ CV4CHL, CVPR 2026 @ MMRAgI, ICLR 2026 @ ES-Reasoning.
Organizer:
📝 Selected Publications:
* Equal contribution. ♡ Project lead. ✉ corresponding/co-corresponding author.
Also see Publications Page and Google Scholar.
-
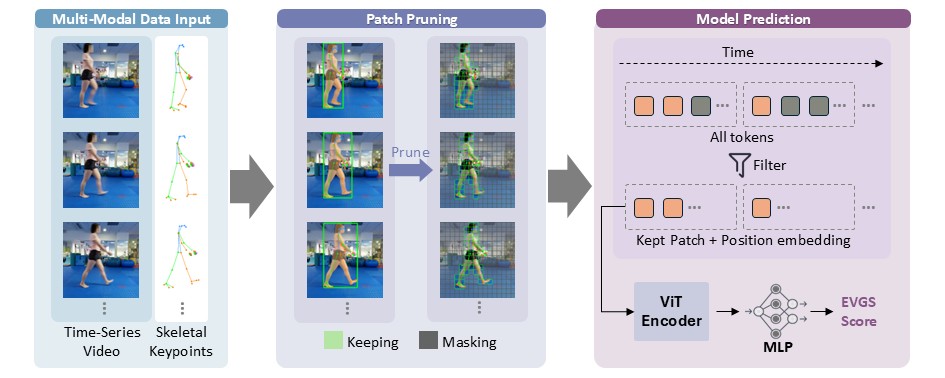 Decoding Children's Gait Behavior
Decoding Children's Gait Behavior
Yifan Shen*, Boyi Li*, Meihuan Huang*, Yuanzhe Liu*, Xu Cao*,♡, Jinyang Jin, Zhengyuan Li, Anglin Liu, Junho Kim, Jingyuan Zhu, Lan Fangzhou, Jianguo Cao, Jintai Chen, Ismini Lourentzou, James M. Rehg✉
The first and largest repository of multi-camera gait videos of children with developmental motor conditions, containing both clinically relevant assessments (EVGS and GVS) and rich frame-level annotations. The first comprehensive assessment of the ability of SoTA open and closed VLMs to decode the subtle signs of gait abnormalities from video, and find that out-of-the-box models are ineffective for this task. A novel video analysis method that is the current SoTA for the automated inference of EVGS and GVS scores from children's videos.ECCV 2026 -
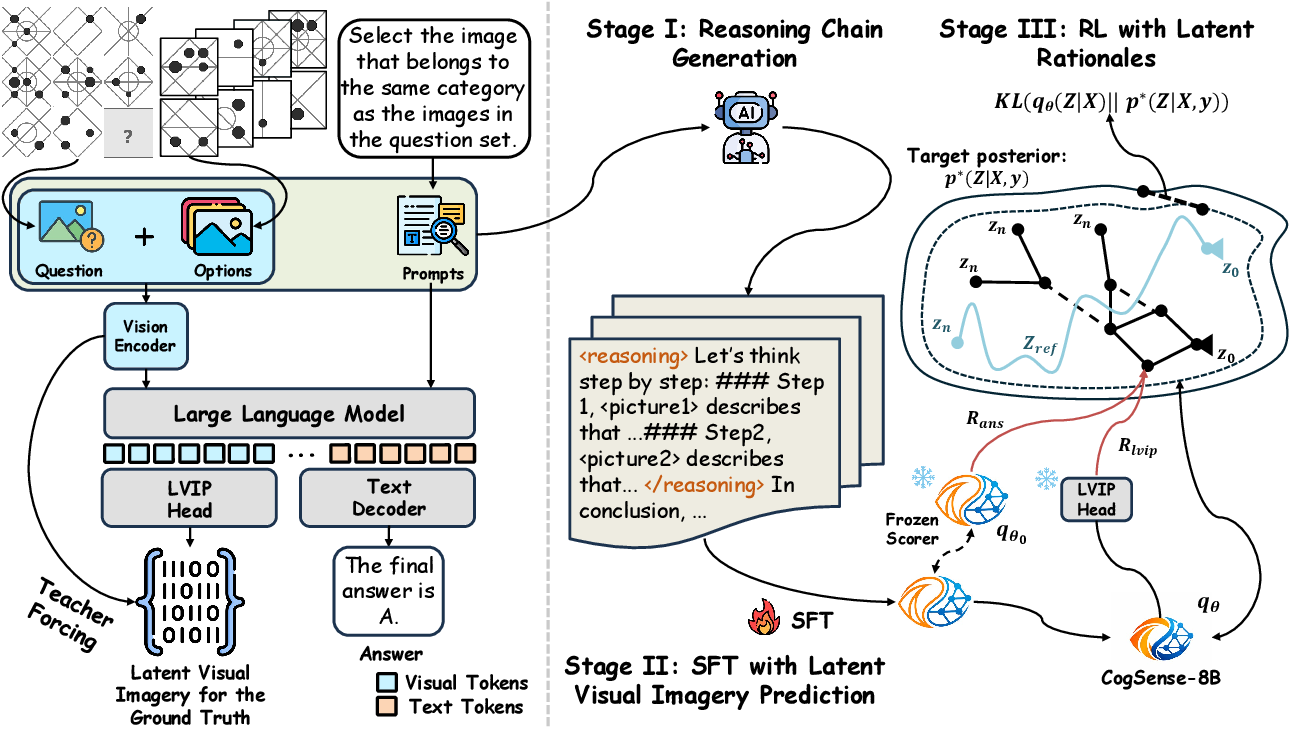 Toward Cognitive Supersensing in Multimodal Large Language Model
Toward Cognitive Supersensing in Multimodal Large Language Model
Boyi Li*, Yifan Shen*,♡, Yuanzhe Liu*, Yifan Xu, Jiateng Liu, Xinzhuo Li, Zhengyuan Li, Jingyuan Zhu, Yunhan Zhong, Fangzhou Lan, Jianguo Cao, James M. Rehg, Heng Ji, Ismini Lourentzou✉, Xu Cao✉
A novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions.arXiv Preprint -
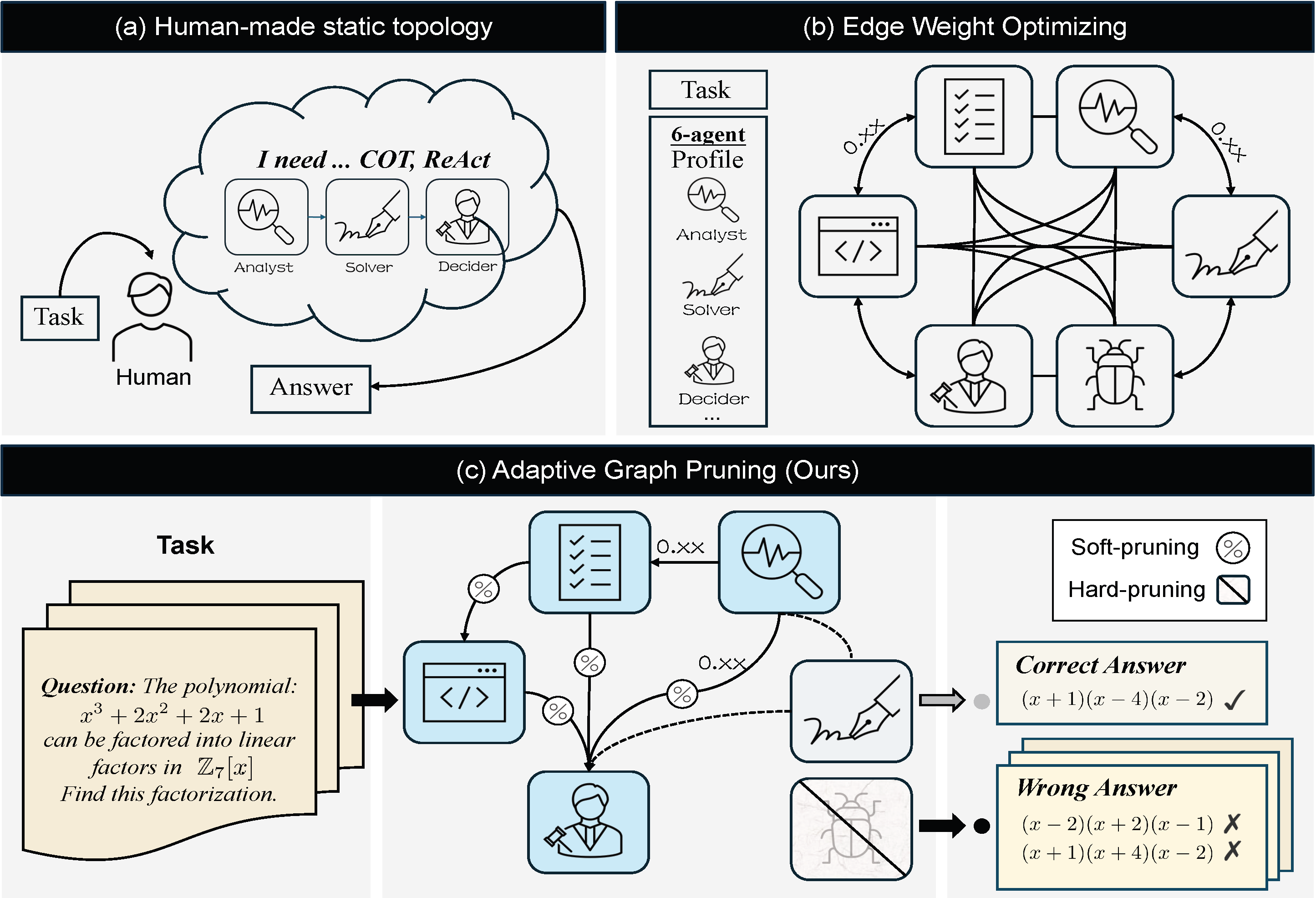 Adaptive Graph Pruning for Multi-Agent Communication
Adaptive Graph Pruning for Multi-Agent Communication
Boyi Li*, Zhonghan Zhao*,♡, Der-Horng Lee✉, Gaoang Wang✉
A novel task-adaptive multi-agent collaboration framework that jointly optimizes agent quantity (hard-pruning) and communication topology (soft-pruning), dynamically constructing optimized communication topologies tailored specifically to individual tasks.ECAI 2025 -
 See and think: Embodied agent in virtual environment
See and think: Embodied agent in virtual environment
Zhonghan Zhao*, Wenhao Chai*,♡, Xuan Wang*, Boyi Li, Shengyu Hao, Shidong Cao, Tian Ye, Jenq-Neng Hwang, Gaoang Wang✉
A comprehensive and visionary embodied agent in the Minecraft virtual environment comprises three key components: vision perception, language instruction, and code action.ECCV 2024
News:
- Jul. 2024 Our paper See and think: Embodied agent in virtual environment is accepted by ECCV 2024.
- Jul. 2025 Our paper Adaptive Graph Pruning for Multi-Agent Communication is accepted by ECAI 2025 and selected as a spotlight paper.
- Jan. 2026 It is a great honor to serve as one of the co-organizers of CVPR 2026 Workshop on Computer Vision for Children (CV4CHL).
- Mar. 2026 Our paper The 1st AI Children Challenge is accepted by the proceeding track of CVPR 2026 Workshop on Computer Vision for Children (CV4CHL).
- May. 2026 The 1st AI Children Challenge is successfully held and all evaluations are completed! Thanks to all the teams for their support and participation!
- Jun. 2026 My personal citation reached 100! It's a meaningful milestone for me. Thanks to all my mentors for their help and support!
- Jun. 2026 Our paper Decoding Children's Gait Behavior is accepted by ECCV 2026.